skyfans之每天一个Liunx命令系列之四十八:awk之2
本文共 1614 字,大约阅读时间需要 5 分钟。
今天我们继续来学习每天一个命令,今天我们继续学习章节内容:查找类命令(SEARCH),这章里将包括我们运维常用的三剑客内容,今天我们继续来学习awk(文本和数据进行处理,也可以理解为一种编程语言)命令。它能使用正则表达式等其他过滤条件搜索文本,并把匹配的内容打印出来。
写在前面,上一篇中,我们在文中为了方便大家理解,使用第一段,第二段的字样,是为了方便按顺序理解,理论上专业点需要叫做域,$数字是代表的不同区域!!
awk工作流程说明:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域。其中,"$0"的参数则表示所有域, “$1"参数表示第一个域,”$n"表示第n个域。默认域分隔符是"空白键" 或 “[tab]键”。上节我们讲解的内容是老师自己创造的文件,那我们在日常运维中,很多的时候都是查看系统类的文件,我们来查看下存放用户名密码的文件/etc/passwd。
1.使用过滤分隔符查看
格式说明:awk -F分隔符 空格 ‘{print $第几个域}’ 文件名称(绝对路径)
使用我们上章节讲解的命令:
awk '{print $1}' /etc/passwd 
好,那这种情况下,我们如何查询我们想要的域呢?这时候-F就体现了它的作用。注意:后有空格!!由于不过滤显示的内容会过多,这里过滤只显示skyfans用户的内容。
awk -F: '{print $1}' /etc/passwd |grep skyfans 
awk -F: '{print $1,$6}' /etc/passwd |grep skyfans 
为了更多的测试,我这里又创建了一个不要face的文件,文件内容整体如下:
说明:第一行的逗号为英文逗号,第三行的为中文逗号。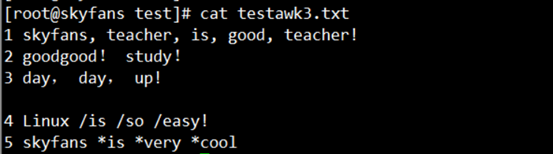 继续测试, 我们已逗号(英文)进行分割查询:
继续测试, 我们已逗号(英文)进行分割查询: awk -F, '{print $1,$2}' testawk3.txt 
2.加入行匹配内容
格式说明:awk -F分隔符 空格 ‘{NR==行数 print $第几个域}’ 文件名称(绝对路径)
这次我们进行星号的分隔,文件中只有第6行存在* 的内容,输入命令如下:
awk -F* 'NR==6{print $1,$3}' testawk3.txt 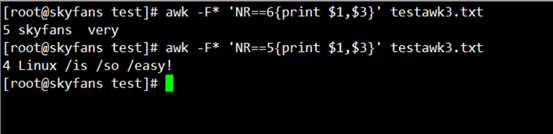
awk -F'*' 'NR==6{print $1,$4}' testawk3.txtawk -F'*' 'NR=='6'{print $1,$4}' testawk3.txtawk -F'*' 'NR=='6' {print $1,$4}' testawk3.txt 
好,与其不如我们多测试点吧,强迫症患者来了,哈哈!!那如果我们想看第5行和第6行的内容呢?
awk -F: 'NR==5||NR==6{print}' testawk3.txt 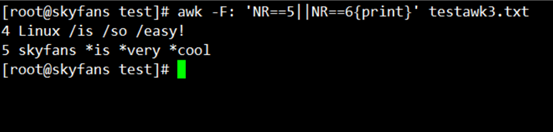
3.显示每行有多少个字段
awk -F: '{print NF}' /etc/passwd 
awk '{print NF}' testawk3.txt 
转载地址:http://zfie.baihongyu.com/
你可能感兴趣的文章
List数组排序
查看>>
VMware vSphere 离线虚拟机安装 BIND 9
查看>>
说说第一份工作
查看>>
dojo/request模块整体架构解析
查看>>
dojo/aspect源码解析
查看>>
Web性能优化:What? Why? How?
查看>>
Javascript定时器学习笔记
查看>>
dojo的发展历史
查看>>
Angular2笔记:NgModule
查看>>
Liunx百宝箱(Centos补充)
查看>>
Python存储系统(Redis)
查看>>
C语言指针收藏
查看>>
.net 4种单例模式
查看>>
T4 生成数据库实体类
查看>>
C#搞个跨平台的桌面NES游戏模拟器
查看>>
手把手教你安装Eclipse最新版本的详细教程 (非常详细,非常实用)
查看>>
《带你装B,带你飞》pytest成魔之路4 - fixture 之大解剖
查看>>
互联网App应用程序测试流程及测试总结
查看>>
根据轨迹分析出用户家在哪
查看>>
PostgreSQL查询表名称及表结构
查看>>